
🎓 About Me
I am currently a Ph.D. student at the College of Computer Science and Artificial Intelligence, Fudan University. My research focuses on reinforcement learning algorithms, large language models, and intelligent agents, with a particular emphasis on advancing the fields of natural language processing and automated content creation.
🔥 News
- 2026.05: One paper accepted to ICML 2026.
- 2026.04: Two papers accepted to ACL 2026.
- 2026.02: One paper accepted to ICLR 2026.
- 2025.10: One paper accepted to NeurIPS 2025 Datasets and Benchmarks Track.
- 2025.05: One paper accepted to ACL 2025.
📝 Selected Publications
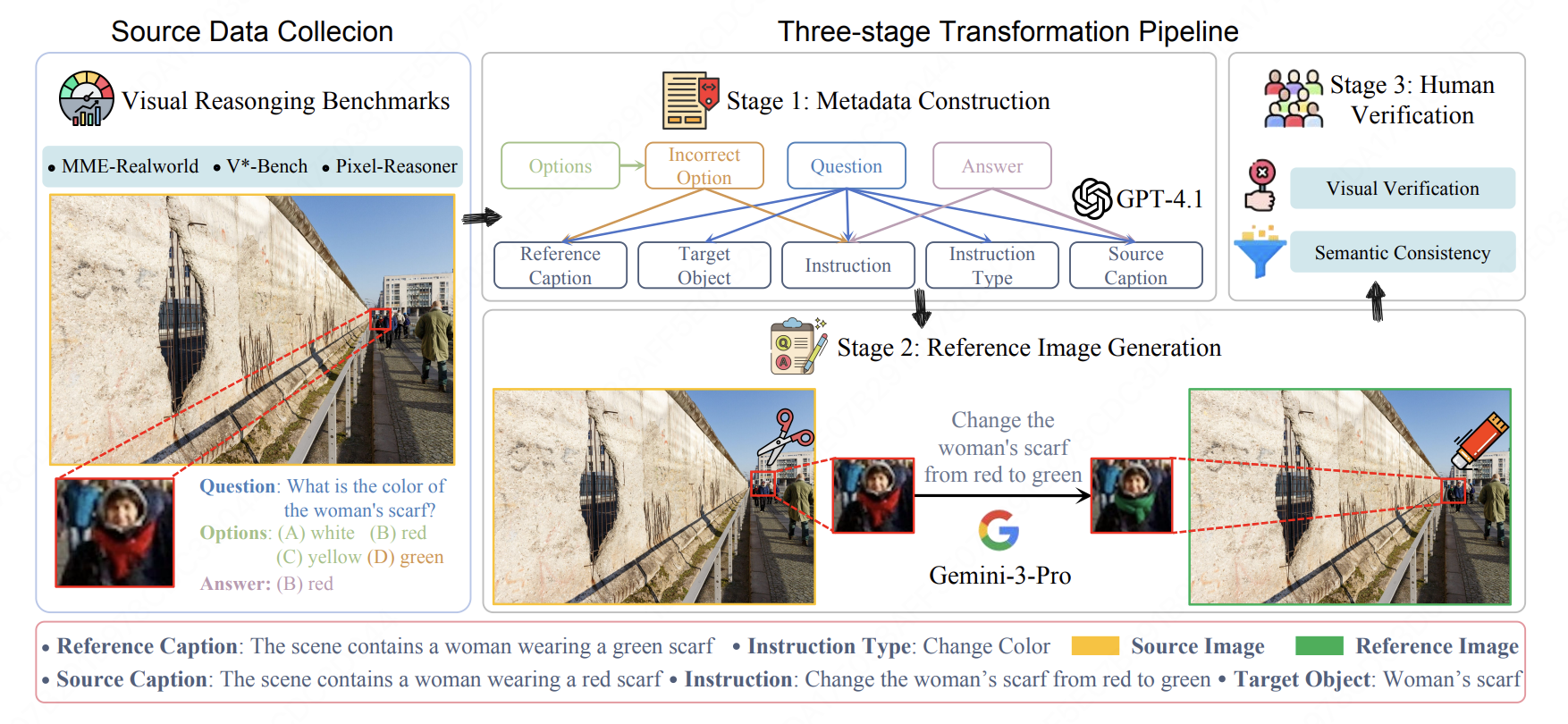
DLEBench: Evaluating Small-scale Object Editing Ability for Image Editing Models [Paper]
Shibo Hong*, Boxian Ai*, Jun Kuang, Wei Wang, FengJiao Chen, Zhongyuan Peng, Chenhao Huang, Yixin Cao†
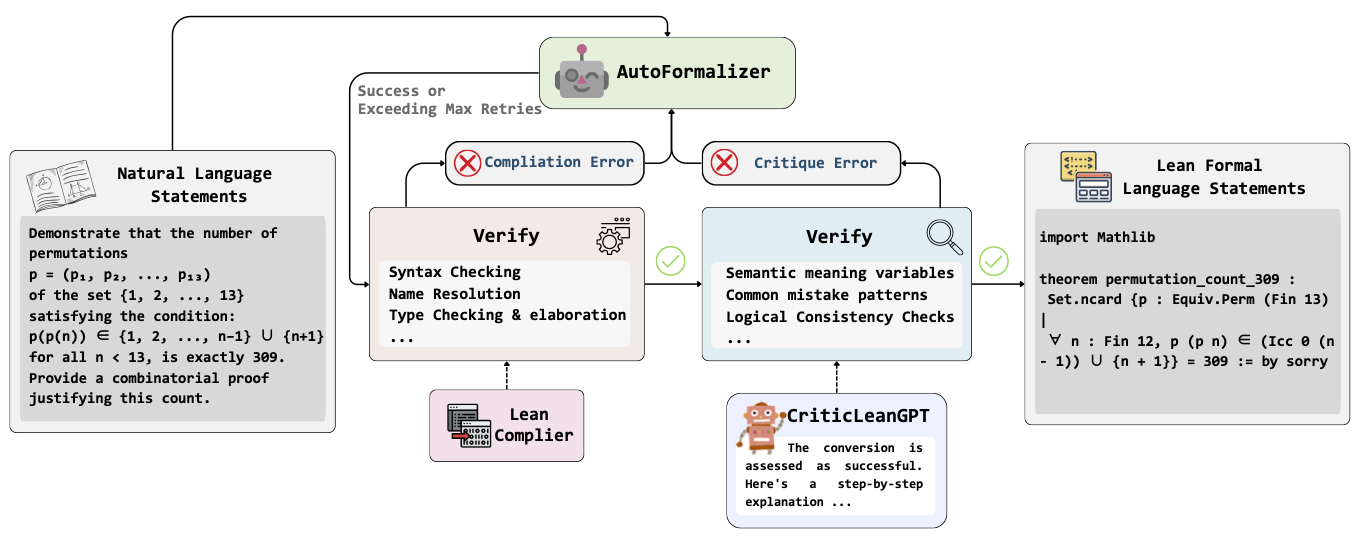
CriticLean: Critic-Guided Reinforcement Learning for Mathematical Formalization [Paper] [Github] [Huggingface]
Zhongyuan Peng*, Yifan Yao*, Kaijing Ma*, Shuyue Guo, Yizhe Li, Yichi Zhang, Chenchen Zhang, Yifan Zhang, Zhouliang Yu, Luming Li, Minghao Liu, Yihang Xia, Jiawei Shen, Yuchen Wu, Yixin Cao, Zhaoxiang Zhang, Wenhao Huang, Jiaheng Liu†, Ge Zhang†
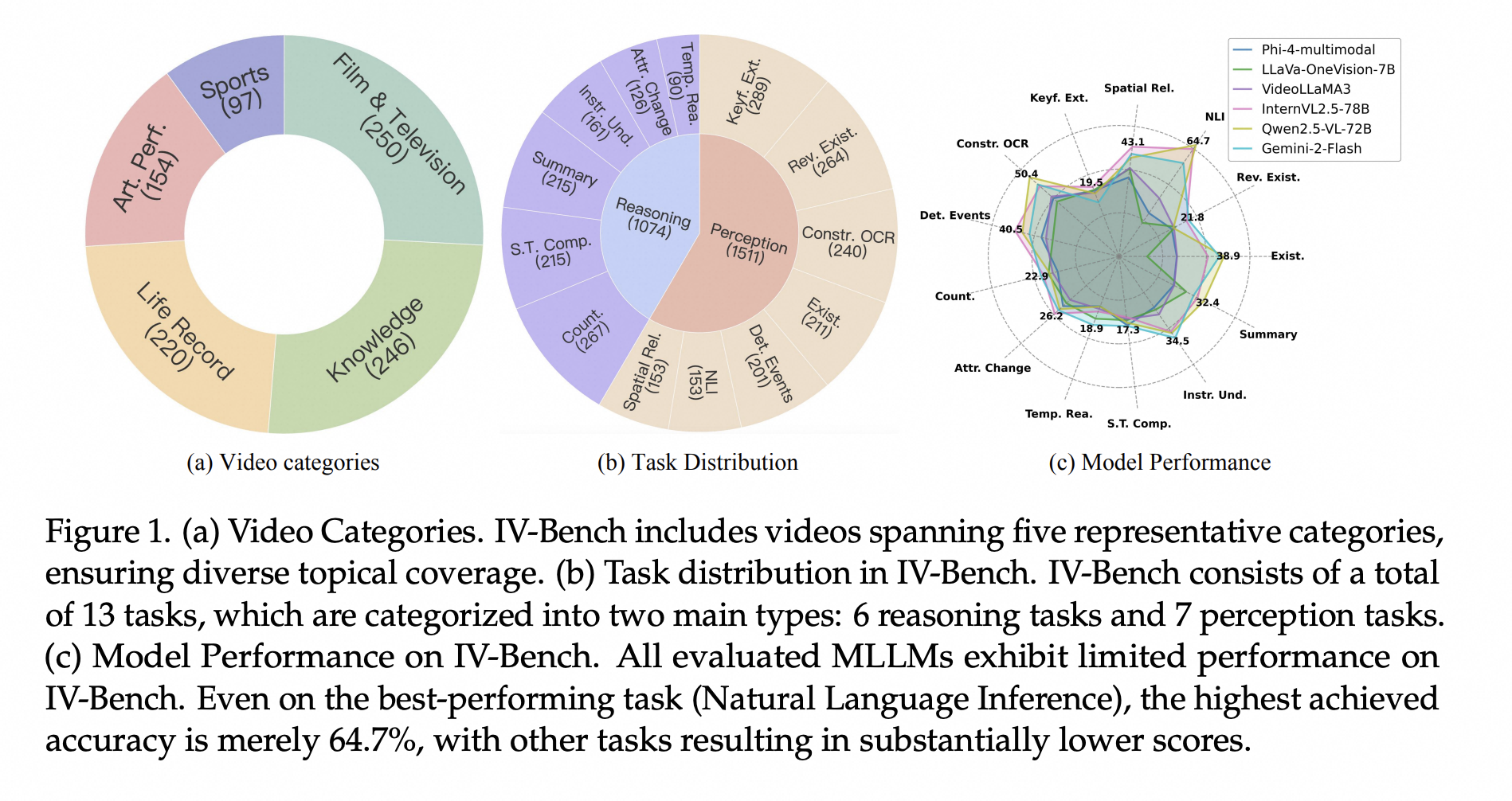
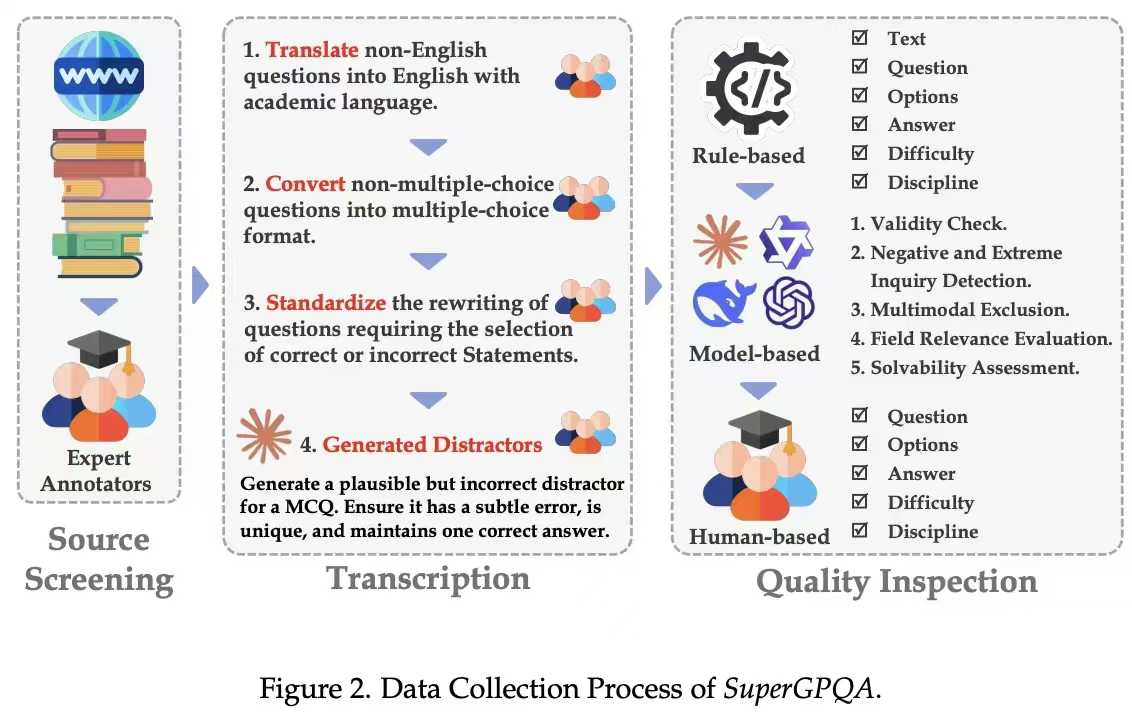
SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines [Paper] [Github] [Huggingface]
M-A-P Team
NeurIPS Dataset and Benchmark Track 2025
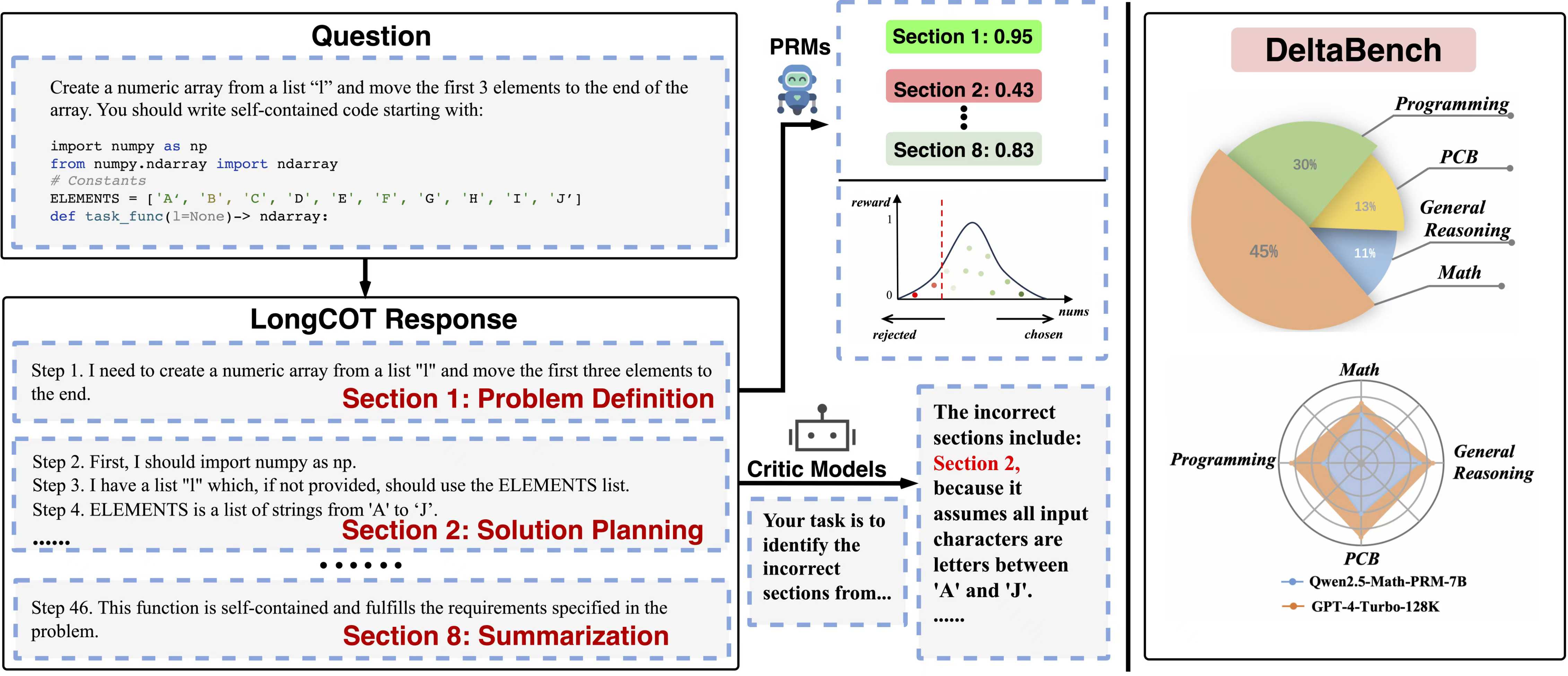
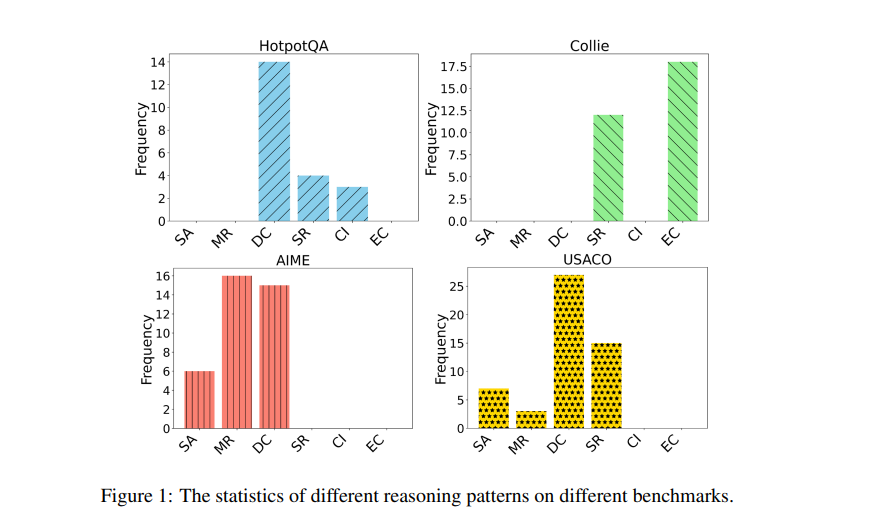
A Comparative Study on Reasoning Patterns of OpenAI’s o1 Model [Paper] [Github]
Siwei Wu*, Zhongyuan Peng*, Xinrun Du*, Tuney Zheng*, Minghao Liu, Jialong Wu, Jiachen Ma, Yizhi Li, Jian Yang, Wangchunshu Zhou, Qunshu Lin, Junbo Zhao, Zhaoxiang Zhang, Wenhao Huang, Ge Zhang†, Chenghua Lin†, J.H. Liu†
The International Conference on Learning Representations (ICLR) 2025 Workshop on Open Science for Foundation Models (SCI-FM)
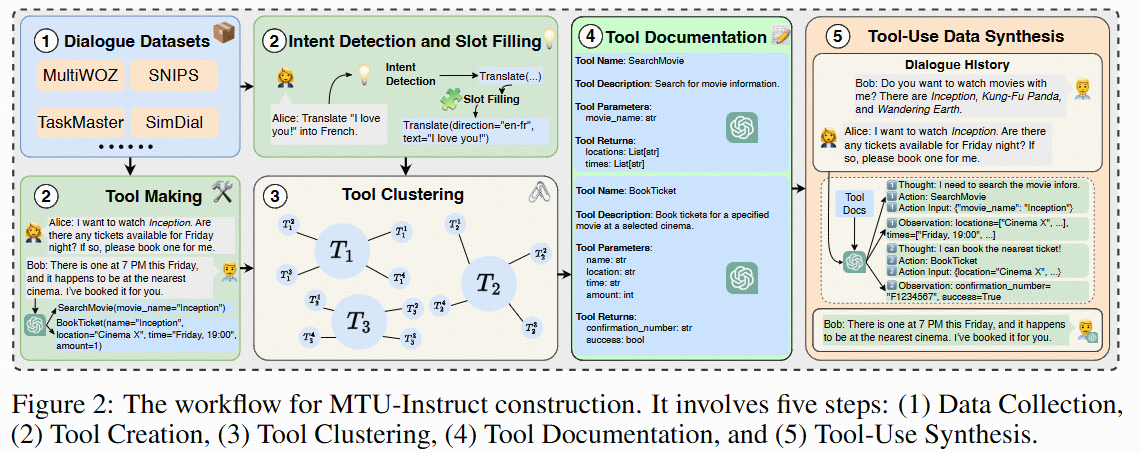
MTU-Bench: A Multi-granularity Tool-Use Benchmark for Large Language Models [Paper] [Github] [Huggingface]
Pei Wang*, Yanan Wu* Zekun Wang*, Jiaheng Liu†, Xiaoshuai Song, Zhongyuan Peng, Ken Deng, Chenchen Zhang, Jiakai Wang, Junran Peng, Ge Zhang, Hangyu Guo, Zhaoxiang Zhang, Wenbo Su, Bo Zheng
The International Conference on Learning Representations (ICLR) 2025
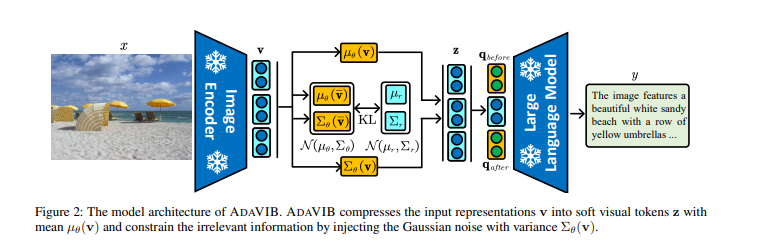
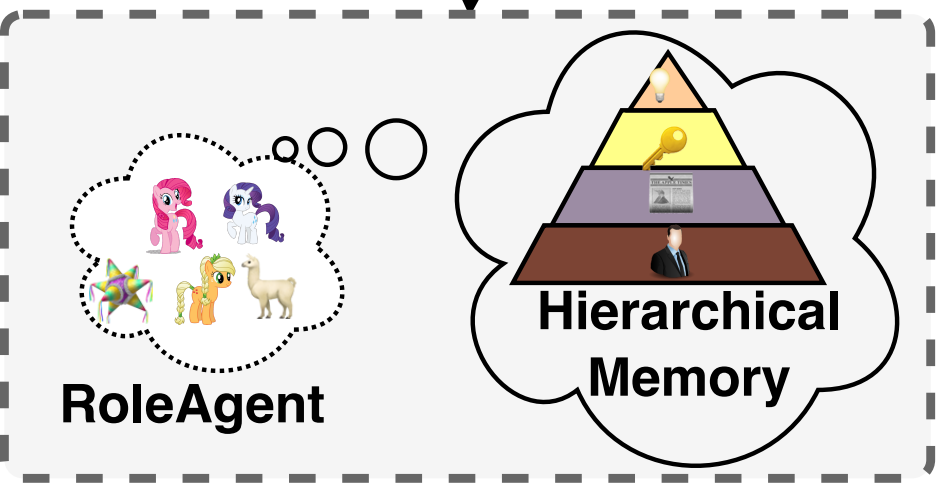
RoleAgent: Building, Interacting, and Benchmarking High-quality Role-Playing Agents from Scripts [Paper]
Jiaheng Liu*, Zehao Ni*, Haoran Que*, Tao Sun, Zekun Wang, Jian Yang, Jiakai Wang, Hongcheng Guo, Zhongyuan Peng, Ge Zhang, Jiayi Tian, Xingyuan Bu, Ke Xu, Wenge Rong, Junran Peng†, Zhaoxiang Zhang
NeurIPS Dataset and Benchmark Track 2024

RoleLLM: Benchmarking, Eliciting, and Enhancing Role-Playing Abilities of Large Language Models [Paper] [Code]
Zekun Moore Wang*, Zhongyuan Peng*, Haoran Que*, Jiaheng Liu†, Wangchunshu Zhou, Yuhan Wu, Hongcheng Guo, Ruitong Gan, Zehao Ni, Jian Yang, Man Zhang, Zhaoxiang Zhang†, Wanli Ouyang, Ke Xu, Stephen W. Huang, Jie Fu, Junran Peng
Findings of the Association for Computational Linguistics (Findings of ACL) 2024
📄 Pre-Prints
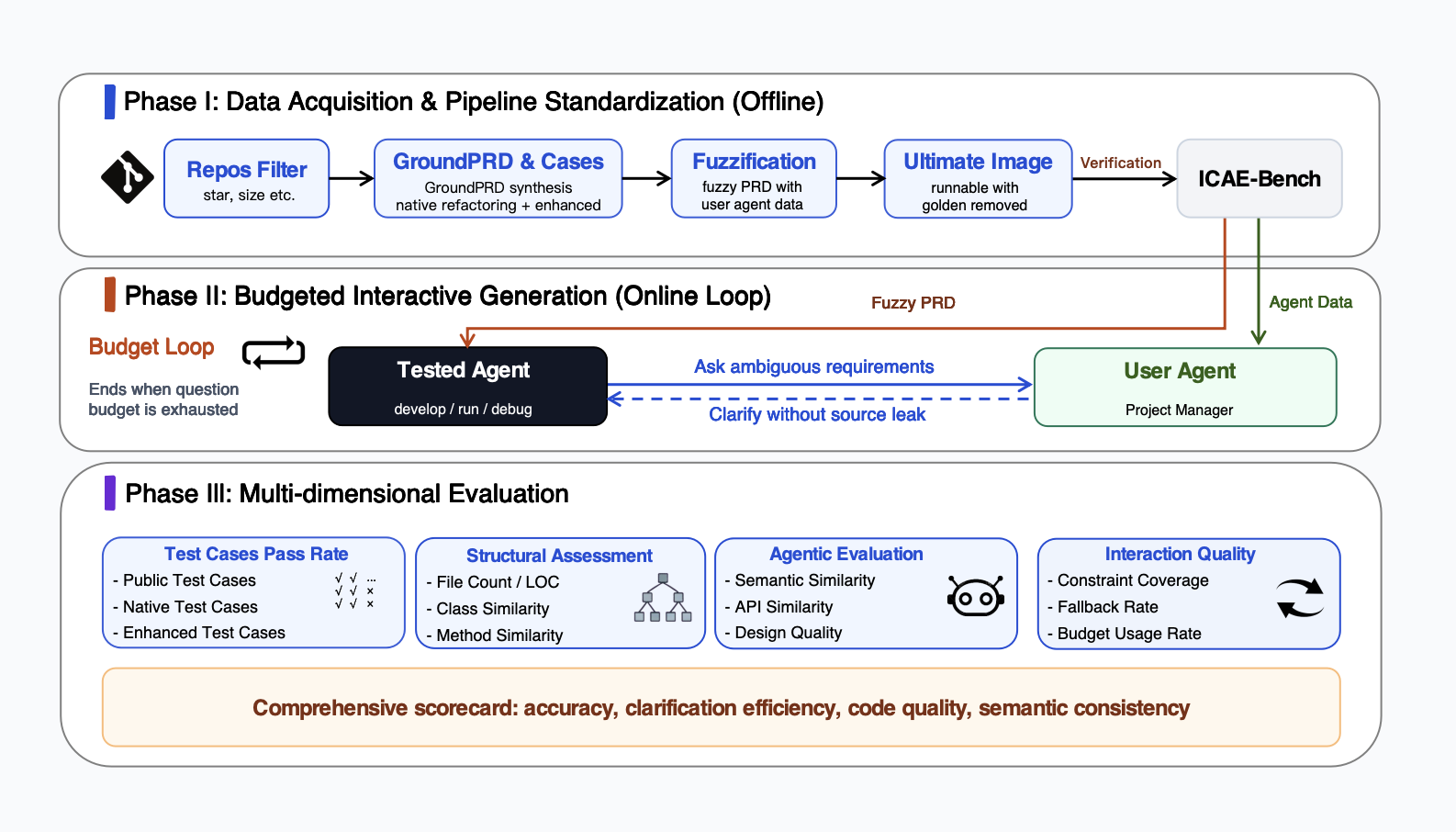
ICAE-Bench: Evaluating Coding Agents as Interactive Project Builders [Github]
Zhongyuan Peng*, Dan Huang*, Chuyu Zhang, Caijun Xu, Changyi Xiao, Shibo Hong, David Lo, Lin Qiu, Xuezhi Cao, Jiyuan He†, Yixin Cao†
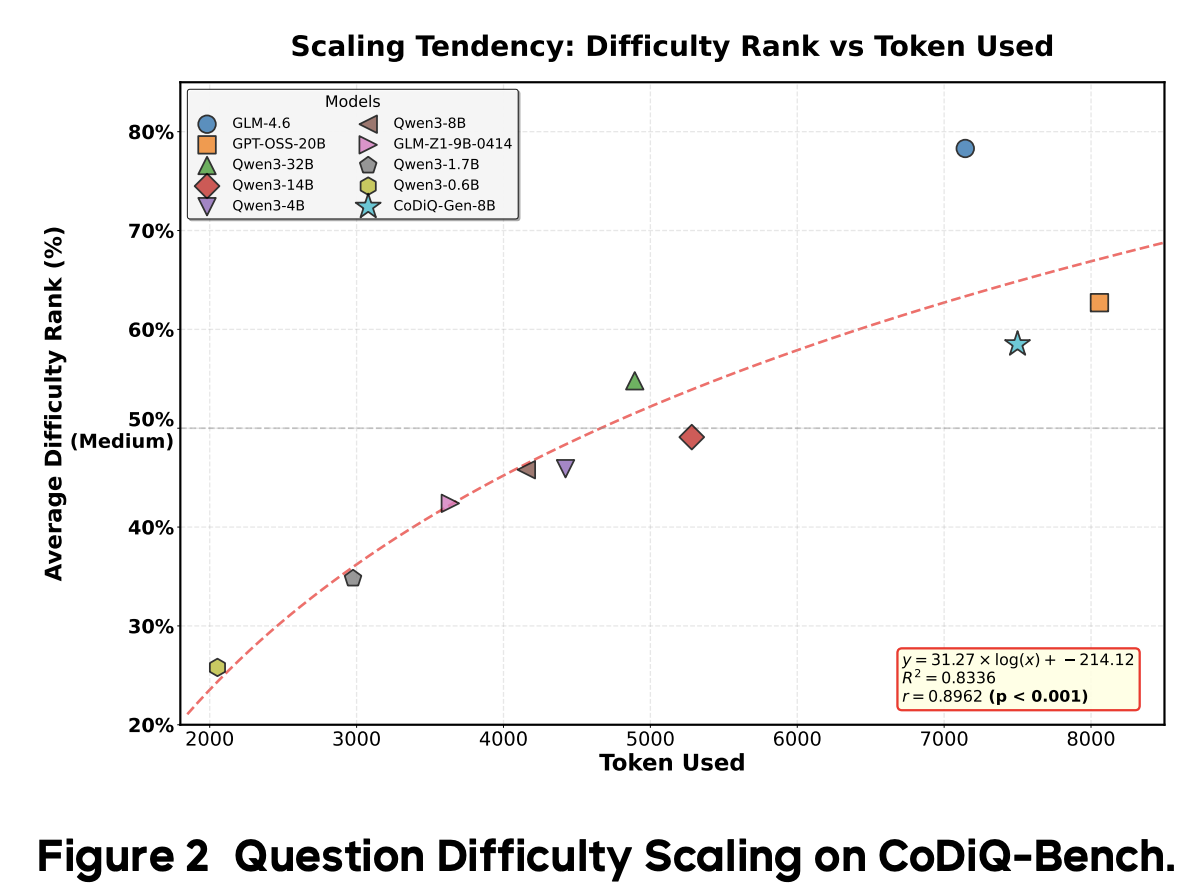
CoDiQ: Test-Time Scaling for Controllable Difficult Question Generation [Paper] [Github] [Huggingface]
Zhongyuan Peng, Caijun Xu, Changyi Xiao, Shibo Hong, Eli Zhang†, Stephen Huang, Yixin Cao†
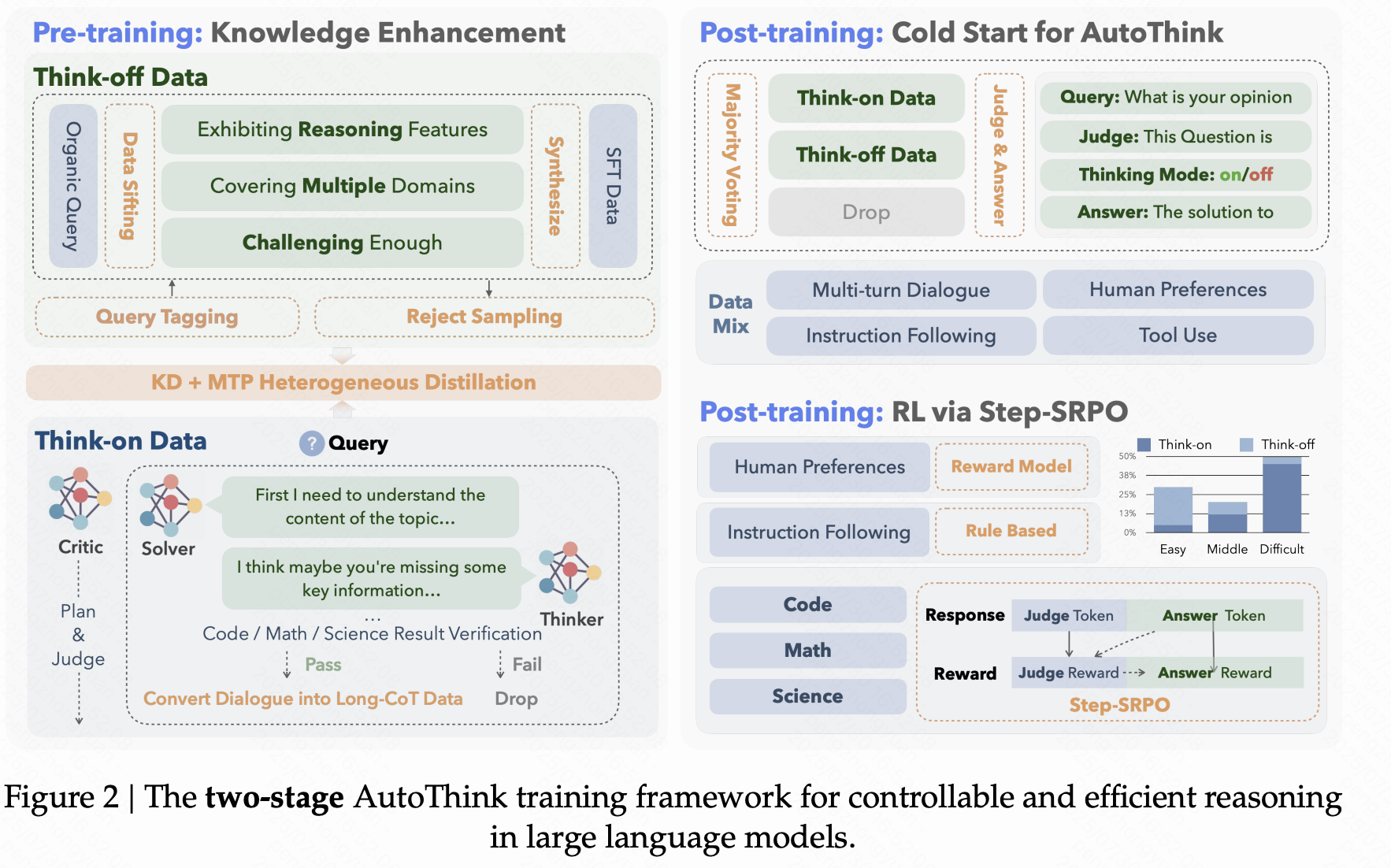
KAT-V1: Kwai-AutoThink Technical Report [Paper]
Zizheng Zhan*†, Ken Deng*, Huaixi Tang*, Wen Xiang*, Kun Wu*, Weihao Li, Wenqiang Zhu, Jingxuan Xu, Lecheng Huang, Zongxian Feng, Shaojie Wang, Shangpeng Yan, Xuxing Chen, Jiaheng Liu, Zhongyuan Peng, Zuchen Gao, Haoyang Huang, Xiaojiang Zhang, Jinghui Wang, Zheng Lin, Mengtong Li, Huiming Wang, Ziqi Zhan, Yanan Wu, Yuanxing Zhang, Jian Yang, Guang Chen, Haotian Zhang, Bin Chen, Bing Yu
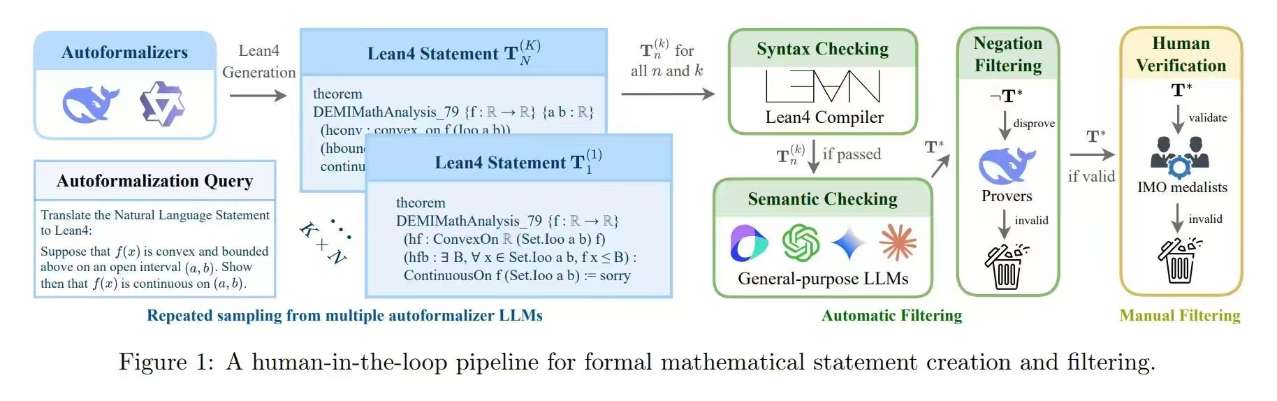
FormalMATH: Benchmarking Formal Mathematical Reasoning of Large Language Models [Paper] [Github] [Huggingface]
Zhouliang Yu*, Ruotian Peng*, Keyi Ding*, Yizhe Li, Zhongyuan Peng, Minghao Liu, Yifan Zhang, Zheng Yuan, Huajian Xin, Wenhao Huang, Yandong Wen, Ge Zhang, Weiyang Liu†
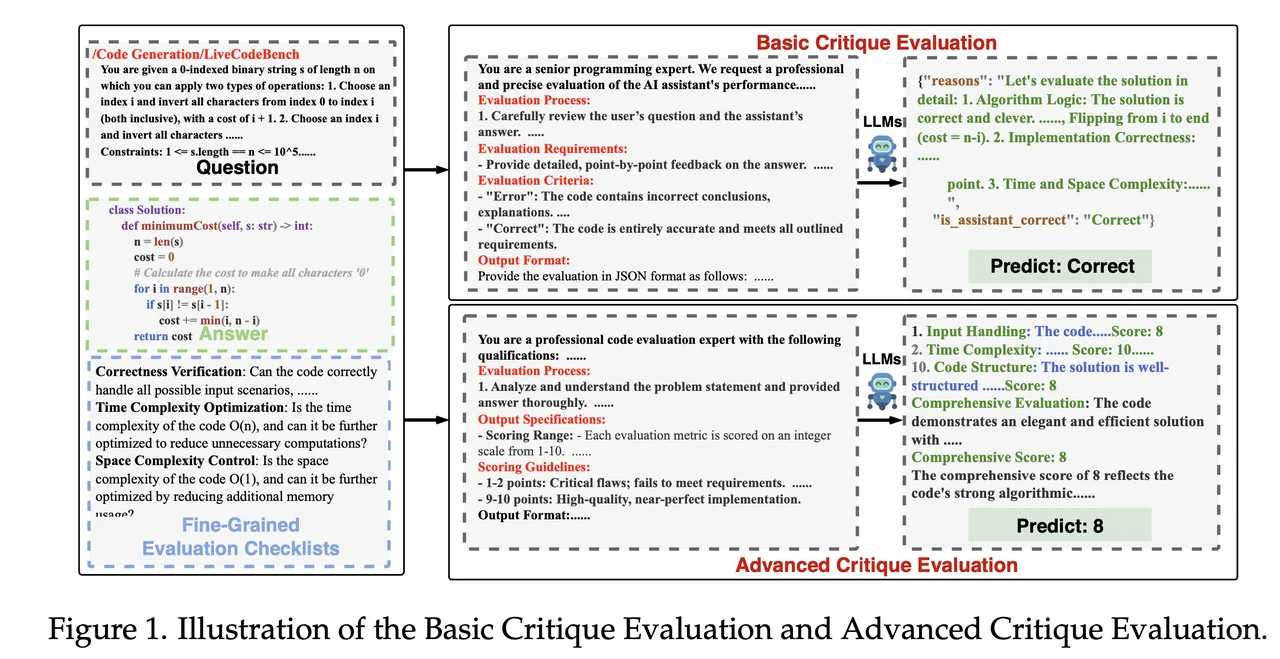
CodeCriticBench: A Holistic Code Critique Benchmark for Large Language Models [Paper] [Github] [Huggingface]
Alexander Zhang*, Marcus Dong*, Jiaheng Liu*†, Wei Zhang, Yejie Wang, Jian Yang, Ge Zhang, Tianyu Liu, Zhongyuan Peng, Yingshui Tan, Yuanxing Zhang, Zhexu Wang, Weixun Wang, Yancheng He, Ken Deng, Wangchunshu Zhou, Wenhao Huang, Zhaoxiang Zhang
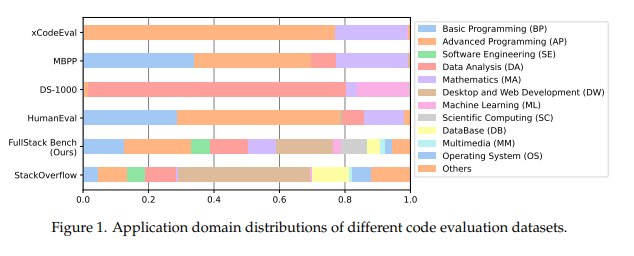
FullStack Bench: Evaluating LLMs as Full Stack Coders [Paper] [Github] [Huggingface]
Siyao Liu*, He Zhu*, Jerry Liu*, Shulin Xin*, Aoyan Li*, Rui Long, Li Chen, Jack Yang, Jinxiang Xia, Z.Y. Peng, Shukai Liu, Zhaoxiang Zhang, Jing Mai, Ge Zhang, Wenhao Huang, Kai Shen†, Liang Xiang†
📖 Experiences
-
Ph.D. in the College of Computer Science and Artificial Intelligence, Fudan University
Date: 2025.09 ~ (now) Supervisor: Prof. Yixin Cao (曹艺馨). -
M.E. in the Institute of Automation, Chinese Academy of Sciences
Date: 2022.09 ~ 2025.06 Supervisor: Prof. Zhaoxiang Zhang (张兆翔). -
B.E. in the School of Computer Science, Wuhan University
Date: 2017.09 ~ 2021.07